Object detection에 활용되는 데이터셋은 정말 다양하다.
사용하는 환경, 출처, 용도에 따라 다양한 영상을 담은 데이터셋이 존재한다.
논문과 함께 github이 함께 올라와 있는 paper with code는 새로운 논문에 대한 새로운 인사이트를 코드와 함께 제공한다.
https://paperswithcode.com/datasets
Papers with Code - Machine Learning Datasets
8760 datasets • 110799 papers with code.
paperswithcode.com
이 곳에서 집계된 데이터 셋만 작성일 기준 8760여 개이다.
그렇다면 이 데이터셋의 형식도 모두 다를까?
다행히도 그건 아니다. 대표적인 데이터셋의 Format이 존재한다. 하지만 데이터셋 형식별로 조금씩 bounding box를 표시하는데 차이가 있다.
또한, Custom Dataset을 활용한다고 했을 때 해당 모델의 데이터 로더 부분에서 인정하는 형식으로 데이터셋의 어노테이션 정보를 맞출 필요가 있다. 따라서 몇 가지 데이터 셋의 형식에 대한 인지가 필요하다.
각 데이터셋의 상세한 설명은 다음 포스팅에서 기약하고 이번엔 Bounding box의 차이에 대해서만 서술하겠다.
COCO
COCO - Common Objects in Context
cocodataset.org
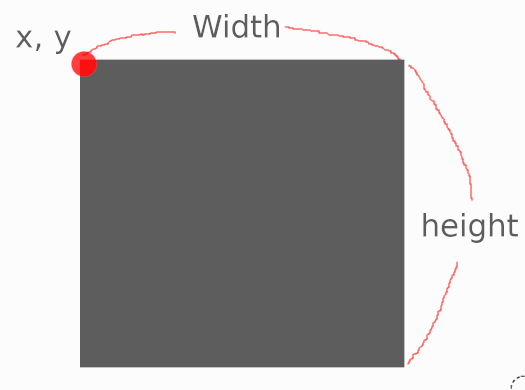
COCO는 Json 파일 형태이고
좌상단의 좌표와 너비 즉 min(x), min(y), width, height이다. 주로 xywh 형태로 부른다.
Pascal VOC
http://host.robots.ox.ac.uk/pascal/VOC/voc2007/
The PASCAL Visual Object Classes Challenge 2007 (VOC2007)
The PASCAL Visual Object Classes Challenge 2007 News 26-Mar-08: Preliminary details of the VOC2008 challenge are now available. 21-Jan-08: Detailed results of all submitted methods are now online. For summarized results and information about some of the b
host.robots.ox.ac.uk
pascal voc는 주로 Xml 파일이고
좌상단, 우하단 즉, min(x), min(y), max(x), max(y)이다. x1,y1,x2,y2 혹은 xyxy 형태로도 부른다.

Yolo
https://github.com/ultralytics/yolov3
GitHub - ultralytics/yolov3: YOLOv3 in PyTorch > ONNX > CoreML > TFLite
YOLOv3 in PyTorch > ONNX > CoreML > TFLite. Contribute to ultralytics/yolov3 development by creating an account on GitHub.
github.com
Yolo는 image 당 하나의 txt 파일이 존재한다는 점에서 위의 데이터셋들과 차이가 있다.
또한 중심점의 x,y 좌표와 width, height를 bounding box의 정보로 사용하기에 COCO와 유사하지만
Yolo는 중심 좌표를 사용한다는 것을 기억하자
그리고 각 x, y, w, h를 이미지의 사이즈로 나누어 비율을 annotation 정보로 이용한다.
따라서 COCO에서 YOLO형태로 데이터셋을 변환할 경우 각별한 주의가 필요하다.
